 最近很多人问我:能不能让 AI 自动盯着 X(原 Twitter),每天把重要信息整理好推给我?
最近很多人问我:能不能让 AI 自动盯着 X(原 Twitter),每天把重要信息整理好推给我?
我自己折腾了几天,从"浏览器自动登录爬取"一路走到"真正稳定可用的方案",中间踩了不少坑。
这篇文章不讲概念,直接带你跑通两件事:每天早上 8 点自动总结 X 上过去 24 小时的 AI 热点、每小时聚合你关注的几百位大佬的最新推文。全流程配置、避坑点、成本估算都写在里面。
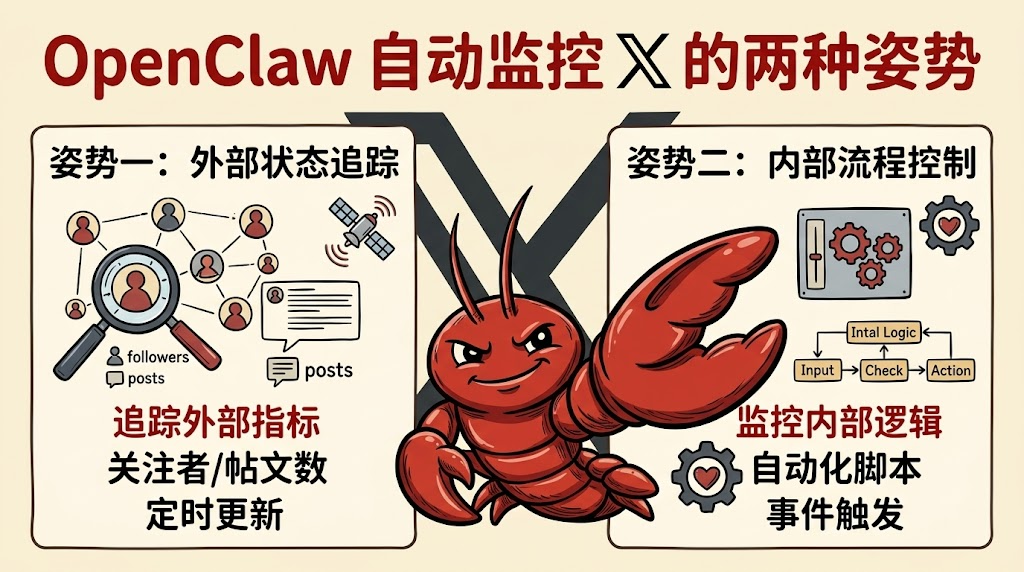
先说结论:两条路,分别解决两件事
监控 X 没有"一招搞定"的方法,因为热点话题和特定账号是两种完全不同的数据形态。
- 热点话题:你不知道谁会发、发什么,需要"按关键词做全网搜索"。
- 大佬动态:你知道具体关注谁,只需要"按用户列表拉推文流"。
对应两个技术路线:热点走 xAI 的 Grok x-search(Grok 自己带 X 搜索能力),大佬走官方的 xurl CLI + X List API。两套方案都跑在 OpenClaw 的 Cron 里,失败重试、推送 Discord 这些 OpenClaw 自带。
成本大概心里有个数:x-search 单次约 0.01~0.02 美元,100 人左右的 List 每小时拉一次,基本在 0.05 美元左右。
方案一:每天早上 8 点总结 X 的 AI 热点
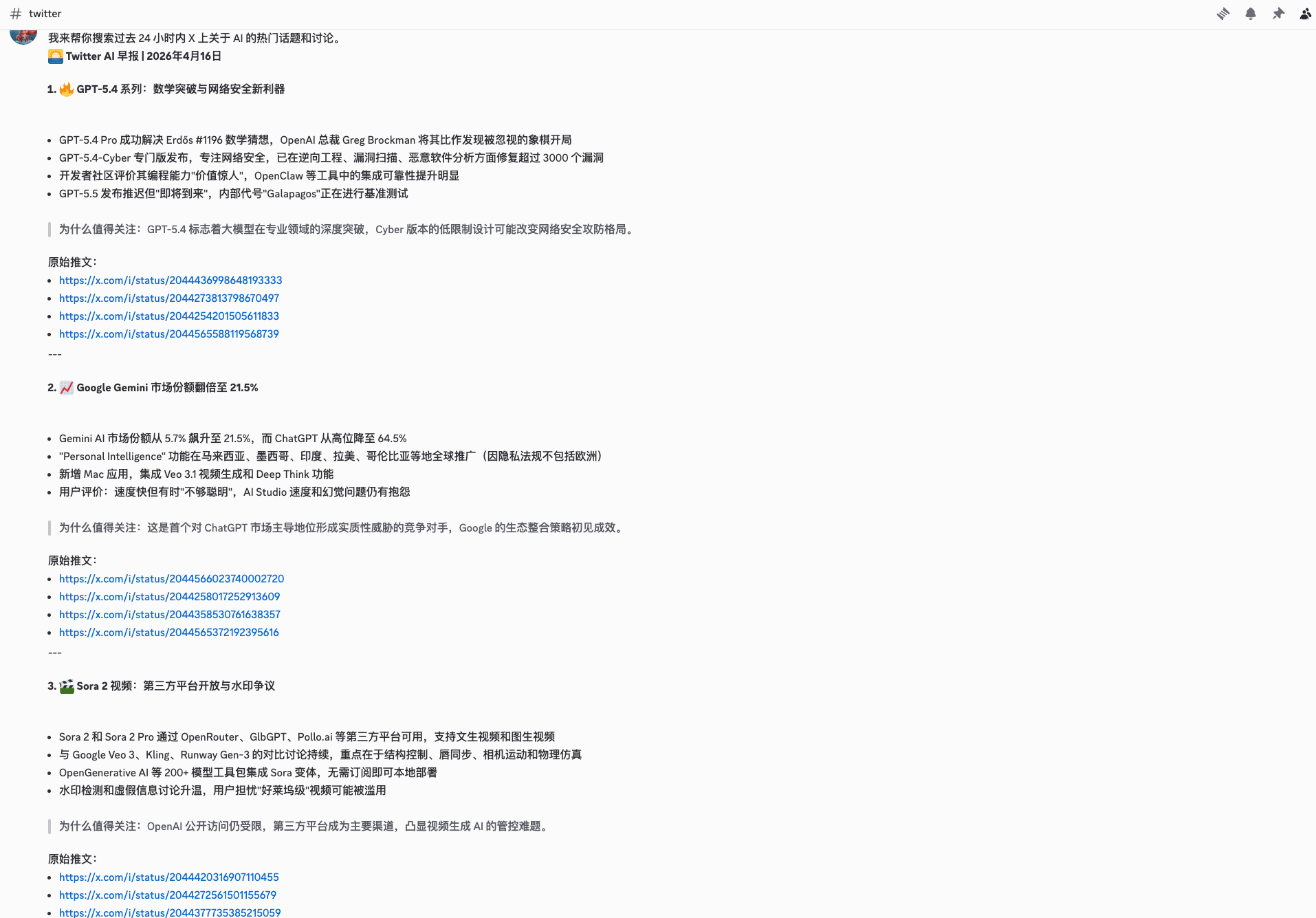
这个方案用 https://clawhub.ai/ 的 x-search Skill,它本质是让 Grok 帮你做一次"有归纳能力的 X 全网搜索",而不是你自己去爬 API。
为什么不用 X 官方 API 做热点搜索
官方搜索 API 成本高、限流严,还得自己写一堆过滤和去重逻辑。 而 x-search 是 Grok 内置能力,你丢一段自然语言 prompt 给它,它会自己去 X 检索、过滤、归纳成话题,省事也省钱。
第一步:购买 xAI 积分
打开 https://console.x.ai/,充值几美元就够用很久。
单次搜索大约 0.01~0.02 美元,一个月 30 次也就几块人民币。
第二步:在 OpenClaw 里启用 x-search Skill
x-search 的 Skill 地址:https://clawhub.ai/jaaneek/x-search。
在 openclaw.json 里开启:
"skills": {
"entries": {
"x-search": {
"enabled": true,
"env": {
"XAI_API_KEY": ""
}
}
}
}XAI_API_KEY 去 console.x.ai 后台生成一个 key 填进去即可。
小提醒:不用自己手动改文件,直接让 OpenClaw 帮你配置就行,它支持自然语言修改 skill。
第三步:写 Cron 调度的 prompt
Cron 里的 prompt 是整个方案的灵魂——写得好,产出的就是一份能直接发的早报;写得糙,就是一堆零散推文罗列。
我跑下来比较顺手的 prompt 如下,你可以直接改用:
帮我搜索 X 上过去 24 小时内关于 AI 的热门趋势、重点讨论和高频话题,整理成一份适合发布到 Discord 的 `Twitter AI 早报`。
要求:
1. 只统计过去 24 小时内的内容,优先选择讨论度高、传播广、互动明显的话题
2. 聚焦 AI 相关内容,包括但不限于:
- 大模型 / AI 产品发布
- OpenAI / Google / Anthropic / xAI / Meta / Microsoft 等动态
- AI 绘图、AI 视频、Agent、编程工具、开源模型
- 行业争议、刷屏观点、重要安全/政策讨论
3. 不要罗列零散推文,要先归纳成 `3-6 个最值得关注的话题`
4. 每个话题都要包含:
- 一个清晰标题
- 2-4 条简要总结
- 1 句"为什么值得关注"
- 2-5 条原始推文链接
5. 优先引用有影响力账号、官方账号、核心参与者或高互动推文
6. 如果多个推文讨论的是同一件事,要合并为一个话题,不要重复
7. 如果过去 24 小时没有特别重大的 AI 新闻,也要总结"讨论最热的话题",不要空缺
输出格式要求:
1. 使用 Discord 支持的 Markdown 格式(**加粗**、`代码`、> 引用)
2. 每个话题使用清晰标题,并配合适当表情符号
3. 推文链接必须用 <> 包裹,避免 Discord 自动嵌入
4. 分段清晰,避免长段落
5. 不要使用表格,使用列表结构
6. 控制整体可读性,适合在 Discord 频道中快速浏览
7. 不要写得像正式新闻稿,要更像"信息密度高的社区早报"
输出结构示例:
**🌅 Twitter AI 早报 | {日期}**
**1. {话题标题}**
- 要点 1
- 要点 2
- 要点 3
> 为什么值得关注:{一句话总结}
原始推文:
- <https://x.com/...>
- <https://x.com/...>
最后增加一个简短总结:
**今日观察**
- 用 2-3 条概括今天 AI 圈在 X 上的整体风向这个 prompt 的核心设计思路是:先让它聚合成话题,再要求引用原始链接。出来的不是信息噪音,而是"你看一眼就知道今天 X 上发生了什么"的早报。
方案二:每小时聚合 100+ 大佬的最新推文

这部分比上面麻烦很多,但一旦跑通,基本上你就不用再手动刷 X 了。
核心思路:用 List,不要循环抓每个人
如果你关注 100 个人,每小时都去挨个调 API,成本会爆炸。 正确做法是把他们都加进一个 X List,然后只拉这一个 List 的推文流——一次调用全拿到。
第一步:OpenClaw 默认已装 xurl Skill
xurl 是 X 官方出的 CLI 工具,OpenClaw 默认带了 xurl Skill,所以你不用从 0 配置,只需要装好本地的 xurl CLI 并完成授权。
第二步:在 X 后台创建 App 并购买积分
打开 console.x.com:
- 创建 app,记好 CLIENT_ID 和 CLIENT_SECRET。
- 购买积分。
- 重点:配置
User authentication settings。
具体这几项:
- App permissions: Read
- Type of App: Native App
- Callback URI / Redirect URI:
http://localhost:8080/callback - Website URL: 填你的博客地址也行
- 其它的不填
这几项任何一个没按上面配,后面 OAuth 授权都会失败,报错长这样:
你无法获得该应用的访问权限。请返回并尝试重新登录。
这个错误我第一次卡了一整晚,别重蹈覆辙。
第三步:装 xurl CLI 并完成授权
安装:
brew install --cask xdevplatform/tap/xurl添加 app:
xurl auth apps add openclaw-miniwen-xurl \
--client-id 你的CLIENT_ID \
--client-secret 你的CLIENT_SECRET设为默认:
xurl auth default openclaw-miniwen-xurlOAuth 授权:
xurl auth oauth2按浏览器提示点允许,回到终端看到成功提示就行。
第四步:一条命令拉 List 推文
下面这条是我反复调优后的最优调用,一次请求同时拿到推文、作者信息、互动数据,不需要额外 API 调用:
xurl "/2/lists/${LIST_ID}/tweets?max_results=${MAX_RESULTS}&tweet.fields=created_at,public_metrics&expansions=author_id&user.fields=id,name,username"关键字段说明:
tweet.fields=created_at,public_metrics:拿到发布时间和点赞、转发数。expansions=author_id+user.fields:同一次请求里把作者昵称和 handle 展开,不用再单独调 user API。
第五步:配套脚本和状态文件
单次调用拿到数据还不够,你还需要记住"哪些推文已经推送过",否则每小时会重复推一遍。
我的做法是用几个小脚本加几个 JSON 状态文件:
| 文件 | 作用 |
|---|---|
fetch-xlist-v2.sh | 调 xurl 获取推文原始数据 |
process-xlist.sh | 流程入口:获取 → 去重 → 总结 → 推送 |
xlist-config.json | 配置(每次条数、总结模型等) |
xlist-read-ids.json | 已推送过的推文 ID |
xlist-reads.json | 推文内容缓存 |
xlist-stats.json | 统计数据 |
脚本内容比较长,这里就不贴了。 OpenClaw 的 workspace 规范会自动帮你放到正确位置,你不用操心路径。
第六步:配置 Cron,自动推送到 Discord
Cron 里填这段 prompt:
获取 X 上指定 List 内的用户的最新推文,然后发布到 Discord 的频道:
1. 运行 /Users/sown/.openclaw/workspace/scripts/process-xlist.sh
2. 如果有新推文,为每条推文生成中文总结(使用 zai/glm-4.7)
3. 按照以下格式将每条新推文单独推送到 Discord 频道:
(这里需要换行)
**{作者显示名}** (@{用户名}) · {相对时间}
{中文总结}
<https://x.com/{用户名}/status/{推文ID}>
(这里需要换行)
说明:
- 相对时间如:15分钟前、30分钟前等
- 每条推文之间加个换行
- 如果没有新推文,不推送消息
- 不要增加任何旁白、解释或引导语
- 不要使用 --- 分隔
- 不要使用标题、代码块、引用块、Markdown heading
- 摘要控制在 40 到 80 字,尽量只保留核心信息
- 整体风格保持简洁、紧凑、适合高频阅读这里有三个经验值得抄走:
- 中文总结用便宜的模型就够(我用的是
zai/glm-4.7),没必要上 GPT-4 级别,成本差十几倍。 - 一定要明确"没有新推文就不推送",否则 Discord 每小时收到一条"没东西"的空消息会非常吵。
- 显式禁止旁白和分隔线,否则模型喜欢自作主张加"以下是您今天的推文",破坏阅读体验。
踩过的坑,和我自己的判断
我最开始没走上面这两条路,而是直接用 OpenClaw 的 browser 功能——打开宿主机浏览器,登陆推特账号,用 Cron 调用 openclaw browser open https://x.com/ 去爬页面内容。
结果是:经常超时,不稳定。
原因也简单:X 的前端是重度懒加载加反爬页面,登录态、cookie、rate limit 任何一个波动都会让爬取失败。
教训:能走官方 API 的绝不要走浏览器自动化。官方通道再贵也比"时灵时不灵"值钱。
走完这一圈,我最大的收获不是"会用 xurl 了",而是三条能迁移到其它自动化任务的经验:
- 选 API 前先问成本:抓单用户贵,抓 List 便宜,思路变一下就差一个数量级。
- 状态文件是这类任务的命脉:没有"已推送记录",任何定时任务都会变成噪音源。
- OpenClaw 的价值在"粘合":x-search、xurl、LLM 总结、Discord 推送,本来是四件事,被 Cron 加 Skill 粘成了一件事。
最后
这套方案我跑了有段时间了,基本不再自己刷 X 的时间线。 早上起来看一眼 Discord 的 AI 早报频道,一小时一次的大佬更新按需点开——信息密度反而比主动刷时间线高。
一个问题想问你:你现在获取 X 信息,是靠刷时间线、靠别人的汇总、还是自己搭了自动化? 评论区聊聊。
接下来我会继续把这类"用 OpenClaw 干掉重复信息劳动"的实战拆成可直接抄的配置。
